Analitycy dysponują bogatym zestawem technik statystycznych, które pozwalają odnaleźć w zachowaniu klientów istotne z biznesowego puntu widzenia prawidłowości. Jedną z bardzo popularnych metod eksploracji i analizy danych są drzewa decyzyjne. Z czego wynika ta atrakcyjność? Drzewa są techniką bardzo elastyczną i można je zastosować do zróżnicowanych danych i problemów badawczych. Zmienne wykorzystane w analizie nie muszą spełniać restrykcyjnych założeń znanych chociażby z modeli regresji liniowej, czy analizy wariancji. I nie trzeba ich specjalnie przekształcać. Z drugiej strony dostarczają one atrakcyjnych wizualnie wyników (reguły decyzyjne w postaci drzewa), których interpretacja jest raczej intuicyjna i nie wymaga zaawansowanej znajomości zawiłych terminów statystycznych.
Oczywiście nie jest tak, że drzewa decyzyjne są tą jedyną techniką, która rozwiąże wszystkie problemy i na koniec podejmie decyzję. Jak w przypadku każdej analizy, wykorzystana technika jest tu tylko narzędziem, które powinno być odpowiednio zastosowane przy świadomości jego zalet i ograniczeń. Przede wszystkim, drzewa decyzyjne wymagają dużych prób, by nauczyć się prawidłowości występujących w danych. W małych próbach może się zdarzyć, że wartości odstające czy przypadkowe zależności będą miały nadmierny wpływ na wyniki. Przy niewystarczającej liczbie obserwacji drzewo może mieć również problem z prawidłowym rozrostem.
Co drzewo chce nam powiedzieć – drzewa a reguły decyzyjne
Pod określeniem „drzewa decyzyjne” kryją się de facto 2 grupy technik analitycznych. W zależności od problemu, z którym drzewo będzie się musiało zmierzyć (czyli poziomu pomiaru zmiennej przewidywanej), wyróżniamy drzewa klasyfikacyjne oraz drzewa regresyjne.
Drzewa klasyfikacyjne to narzędzie klasyfikacji w klasycznym ujęciu. Mając znaną wartość jakościowej (nominalnej lub porządkowej) zmiennej przewidywanej, algorytm będzie starał się jak najlepiej odtworzyć przynależność do poszczególnych jej kategorii za pomocą dostępnych predyktorów. Przekładając na terminologię drzew: algorytm będzie starał się tak podzielić zbiór danych za pomocą zmiennych niezależnych, aby w wyróżnionych w wyniku analizy węzłach końcowych (liściach) występowała tylko jedna kategoria zmiennej przewidywanej. Na podstawie wartości zmiennych zależnych, drzewo klasyfikacyjne będzie więc budować regułę dla każdego węzła końcowego: „jeżeli płeć = kobieta i wykształcenie=wyższe to zmienna przewidywana X = kupi”. Niektóre spośród tych reguł będą trafne w 100%, inne będą miały nieco mniejszą skuteczność. Jak to zmierzyć? Drzewo prognozuje przynależność do kategorii zmiennej zależnej w oparciu o dominantę w każdym węźle końcowym. Przypadki nieprawidłowo sklasyfikowane to błąd, który staramy się zminimalizować. Im mniejszy odsetek przypadków błędnie sklasyfikowanych tym lepiej.
Podobnie jak drzewo klasyfikacyjne, także i drzewo regresyjne dąży do dostarczenia zestawu reguł obarczonych jak najmniejszym błędem prognozy. W przypadku zmiennej ilościowej, wykorzystanie dominanty nie dałoby jednak miarodajnych rezultatów, dlatego też drzewo prognozuje średnią wartość zmiennej zależnej. Przykładowa reguła brzmi więc następująco: „jeżeli płeć=kobieta i wykształcenie=wyższe to średnia wartość X = 3,75”. Jak można się domyślić, błąd prognozy przy takim postępowaniu będzie definiowany jako suma kwadratów odchyleń od średniej w węzłach końcowych. Im mniejsze zróżnicowanie przypadków ze względu na wartości zmiennej zależnej w obrębie wyróżnionych grup, tym model jest lepszy.
Co tutaj wyrosło – interpretacja wyników drzewa regresyjnego
Jak w praktyce wygląda działanie drzewa regresyjnego? Rozważmy przykład. Pewna sieć sklepów spożywczych zebrała informacje o transakcjach dokonywanych przez swoich klientów. Zbadano 351 wylosowanych transakcji zakupowych. Poszukiwaną zmienną zależną jest wartość dokonywanej transakcji. Analizy można dokonać w oparciu o szereg zmiennych niezależnych. Są to:
• płeć osoby dokonującej zakupy (kobieta, mężczyzna),
• cel robienia zakupów (dla siebie, dla znajomych, dla rodziny),
• styl robienia zakupów (codziennie, raz lub kilka razy w tygodniu, rzadziej niż raz w tygodniu),
• wielkość sklepu (mały, średni, duży),
• wykorzystanie kuponów zakupowych (brak, gazetka, email, aplikacja).
Przyjrzyjmy się na początku zmiennej przewidywanej – wartości zakupów. Histogram i tabela zawierająca statystyki opisowe zostały zamieszczone poniżej.
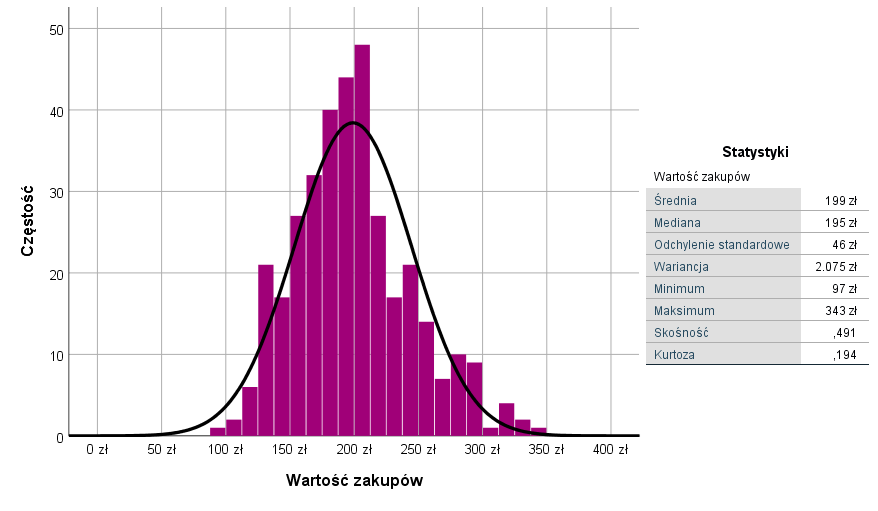
Rysunek 1. Rozkład i statystyki opisowe wartości zakupów
Wartość przeciętnej transakcji wynosiła 199 zł. Wartość odchylenia standardowego mówi nam w uproszczeniu, że prognozując wartość transakcji w oparciu o średnią, pomylimy się średnio o 46 zł. Ta z pozoru niewielka wartość stanowi jednak około 23% średniej wartości zakupów, co brzmi już dużo gorzej. Najdroższe zakupy zrobiono za 343 zł, a najmniejsza transakcja miała wartość 97 zł. Ocena różnicy pomiędzy medianą a średnią, oraz wartości kurtozy i skośności (bliskie 0) potwierdzają wniosek wynikający z oglądu histogramu, że mamy do czynienia ze zmienną o symetrycznym rozkładzie, zbliżonym do rozkładu normalnego. Generalnie nie obserwujemy także wartości odstających. Taka sytuacja jest oczywiście możliwa, choć zdarza się rzadko.
Spróbujmy przeanalizować jak przedstawia się zależność pomiędzy wartością zakupów a dostępnymi zmiennymi niezależnymi za pomocą drzew decyzyjnych. Są one dostępne w PS IMAGO PRO w menu ANALIZA -> KLASYFIKACJA -> DRZEWA KLASYFIKACYJNE. Wykorzystamy CRT jako Metodę wzrostu drzewa. Wskazanie ilościowej zmiennej zależnej automatycznie spowoduje uruchomienie drzewa regresyjnego. Dodatkowe ustawienia algorytmu zostaną omówione w kolejnym artykule. Poniżej zostało zaprezentowane wynikowe drzewo regresyjne dla zmiennej wartość zakupów.
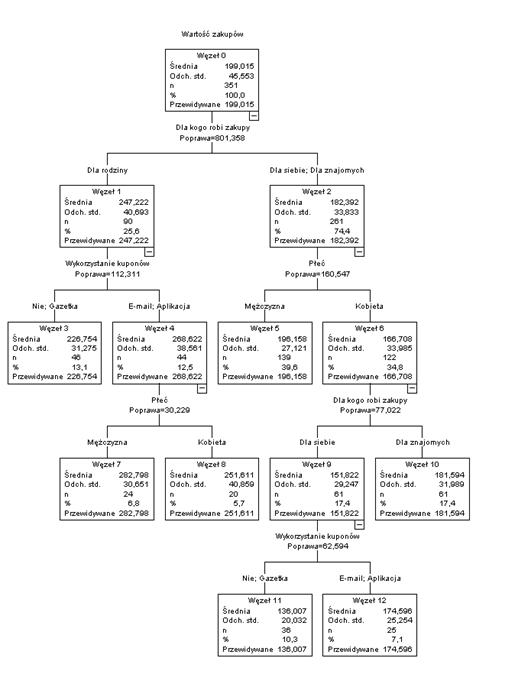
Rysunek 2. Drzewo regresyjne dla zmiennej wartość zakupów
Jak zinterpretować uzyskane wyniki? Nasze drzewo to w istocie wizualizacja reguł decyzyjnych, które możemy odczytać schodząc od ulokowanego na samym szczycie korzenia opisanego jako Węzeł 0 (niestety należy się przyzwyczaić, że drzewa decyzyjne rosną w dół) poprzez poszczególne gałęzie aż do ostatniego węzła, który nie uległ już dalszemu podziałowi. Kolejne rozgałęzienie to podział obserwacji według danej zmiennej niezależnej zawsze na 2 podgrupy (jest to charakterystyczna właściwość algorytmu CRT). Nad każdym węzłem znajdują się opisane kategorie, na podstawie których został uzyskany dany węzeł. Na pierwszym etapie podział drzewa nastąpił ze względu na cel robienia zakupów. Do pierwszej grupy (Węzeł 1) zostały zakwalifikowane osoby, które robią zakupy dla rodziny, zaś do drugiej osoby, które kupowały produkty dla znajomych albo dla siebie.
Warto pamiętać, że drzewo ma strukturę hierarchiczną – każdy kolejny, głębszy podział następuje już tylko w obrębie obserwacji wybranych do węzła na wcześniejszym etapie. Dodatkowo w każdej z wyróżnionych podgrup do dalszych podziałów może być wykorzystany inny predyktor. W opisywanym przypadku podział po lewej stronie drzewa następuje więc tylko wśród osób, które robiły zakupy dla rodziny. W tej grupie nastąpił on ze względu na wykorzystanie kuponów. Po prawej stronie drzewa podział nastąpił ze względu na płeć. Kolejne, coraz głębsze podziały drzewa obrazują kolejne stopnie reguł decyzyjnych. Możemy je porównać do kolejnych, coraz bardziej złożonych filtrów selekcji obserwacji.
Z kolejnych węzłów możemy dodatkowo odczytać statystyki opisowe zmiennej przewidywanej. Opcjonalnie możemy również w kreatorze analizy zamówić wizualizację w postaci wykresów. Szczegóły działania algorytmu zostaną omówione w kolejnym tekście. Na razie poprzestańmy na stwierdzeniu, że drzewo dokonuje podziału optymalnie ze względu na średnią zmiennej zależnej i redukcji rozproszenia wokół niej. W całej próbie, średnia wartość zakupów wynosiła 199 zł. Na pierwszym etapie drzewo podzieliło analizowaną zbiorowość na dwie podgrupy – w węźle pierwszym średnia wynosiła 247 zł, w drugim - 182 zł. Spadły również wartości odchyleń standardowych.
Ostateczny podział przypadków na podgrupy odczytujemy z węzłów końcowych – liści. Są to gałęzie, które po prostu nie uległy już dalszemu podziałowi. W tym momencie powinniśmy więc skupić się na końcowych węzłach o numerach: 3,5,7,8,10, 11 i 12.
Przykładowo przeanalizujmy węzeł 7. Należą do niego osoby, które robią zakupy dla rodziny (pierwszy poziom podziału) oraz korzystają z kuponów z e-maila lub aplikacji i są mężczyznami. Osoby te wydają średnio 283 zł (+/- 31 zł). Algorytm drzewa regresyjnego nie tylko wyselekcjonował grupę klientów wydających zdecydowanie więcej niż wynosi średnia dla całej próby, ale jeszcze dodatkowo udało mu się znacząco zmniejszyć błąd przewidywania w oparciu o średnią.
Na drugim krańcu kontinuum oszczędności znajdują się kobiety robiące zakupy dla siebie i niekorzystające z kuponów lub używające kuponów z gazetki. Jest to węzeł 11 (na samym dole drzewa). Osoby te wydają podczas zakupów średnio 136 zł ,a odchylenie standardowe wynosi w tym przypadku 20. To również znacząca redukcja błędu. Na przykładzie tego węzła możemy także zaobserwować, że raz użyta zmienna (w tym przypadku cel robienia zakupów) może zostać ponownie wykorzystana przez algorytm CRT, jeżeli oczywiście pozwala na to liczba kategorii.
Po zapisaniu do zbioru danych przynależności przypadków do końcowych węzłów zaprezentowanych na drzewie, można poddać je dalszej analizie, np. w procesie poststratyfikacji. Opisy poszczególnych węzłów oraz ich statystyki opisowe zostały zaprezentowane na poniższym wykresie tabelowym. Wizualizacja słupków błędu jest jedną z procedur graficznych dostępnych w PS IMAGO PRO w menu: PREDICTIVE SOLUTIONS -> WYKRESY -> TABELOWE -> SŁUPKI BŁĘDU. Dostępna w programie procedura wykresów tabelowych pozwala na prezentację wielkości podgrup, różnych statystyk opisowych analizowanej zmiennej ilościowej a także bogaty wybór kilku dostępnych wizualizacji.
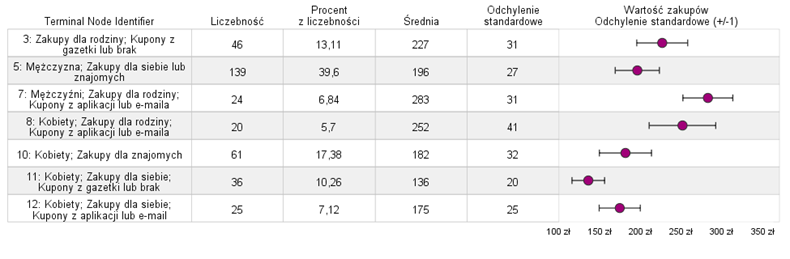
Rysunek 3. Opis grup docelowych wyróżnionych przez drzewo regresyjne
Na tym kończymy pierwszy wpis dotyczący drzew regresyjnych. Skoncentrowaliśmy się w nim przede wszystkim na interpretacji wyników. W kolejnym tekście zostaną szczegółowo omówione zasady działania algorytmu, sposoby kontroli podziału drzewa oraz dodatkowe obiekty wynikowe wzbogacające interpretację reguł decyzyjnych.